
BigQuery サブスクリプションで、Pub/Sub メッセージを BigQuery に直接取り込んでみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、みかみです。
動物病院に予防接種に行ってきました。
待合室まではウキウキだったのに診察室に入るのは拒否して入ったが最後固まる姉(犬)と、終始ごきげんで診察室にも率先して入って看護師さんにも先生にも「なでろ」アピールMAXな弟(犬)。どちらもちょっと恥ずかしいです。
やりたいこと
- BigQuery サブスクリプションを使って、Pub/Sub から直接 BigQuery にデータを取り込みたい。
ニアリアルタイムで BigQuery にデータを取り込みたい場合、まずは Dataflow の利用が思い浮かぶのではないかと思いますが、Cloud Pub/Sub から BigQuery に直接データを取り込めること、ご存知ですか?
以前リリースノートで見て気にはなっていたものの、実際にやってみたことはなかったので、挙動を確認してみました。
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や Pub/Sub など各サービス操作に必要な API の有効化と必要な権限は付与済みです。
なお、文中、プロジェクトIDなど一部の文字は伏字に変更しています。
Pub/Sub メッセージ送信スクリプトを準備
Pub/Sub にメッセージをパブリッシュする、動作確認用の以下の Python スクリプトを publish.py というファイル名で保存しました。
import google.cloud.pubsub_v1 as pubsub
import time
import json
import random
project_id = "[PROJECT_ID]"
topic_name = "tp-pubsub2bq"
publisher = pubsub.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
# sample Data
key1_values = [1, 2, 3, 4]
key2_values = ["aaa", "bbb", "ccc", "ddd"]
key3_values = ["さくらもち", "ラーメン", "自転車", "ソフトウェア開発"]
key4_values = ["ハイブリッドカー", "スーパーマーケット", "コンビニエンスストア", "デジタルカメラ"]
# Pub/Sub Message Publish
count = 0
while count < 10:
message_data = {
"timestamp": time.time(),
"data": {
"key1": random.choice(key1_values),
"key2": random.choice(key2_values),
"nested": {
"key3": random.choice(key3_values),
"key4": random.choice(key4_values)
}
}
}
message_json = json.dumps(message_data).encode("utf-8")
publisher.publish(topic_path, data=message_json)
print(f"publish message: {count+1}")
# 10秒に1回パブリッシュ
time.sleep(10)
count += 1
10秒ごとに timestamp と key1 〜 key4 項目のランダム値のメッセージを作成して Pub/Sub トピックに送信します。
10回送信したら終了します。
BigQuery データセットとテーブルを作成
Pub/Sub メッセージ格納先の、BigQuery データセットをテーブルを作成します。
以下のコマンドで ds_pubsub2bq データセットを作成しました。
bq mk --dataset ds_pubsub2bq
また、以下のコマンドで data_from_pubsub テーブルを作成しました。
bq mk --table ds_pubsub2bq.data_from_pubsub schema.json
テーブルスキーマは以下です。
[
{
"name": "data",
"type": "JSON",
"mode": "NULLABLE"
}
]
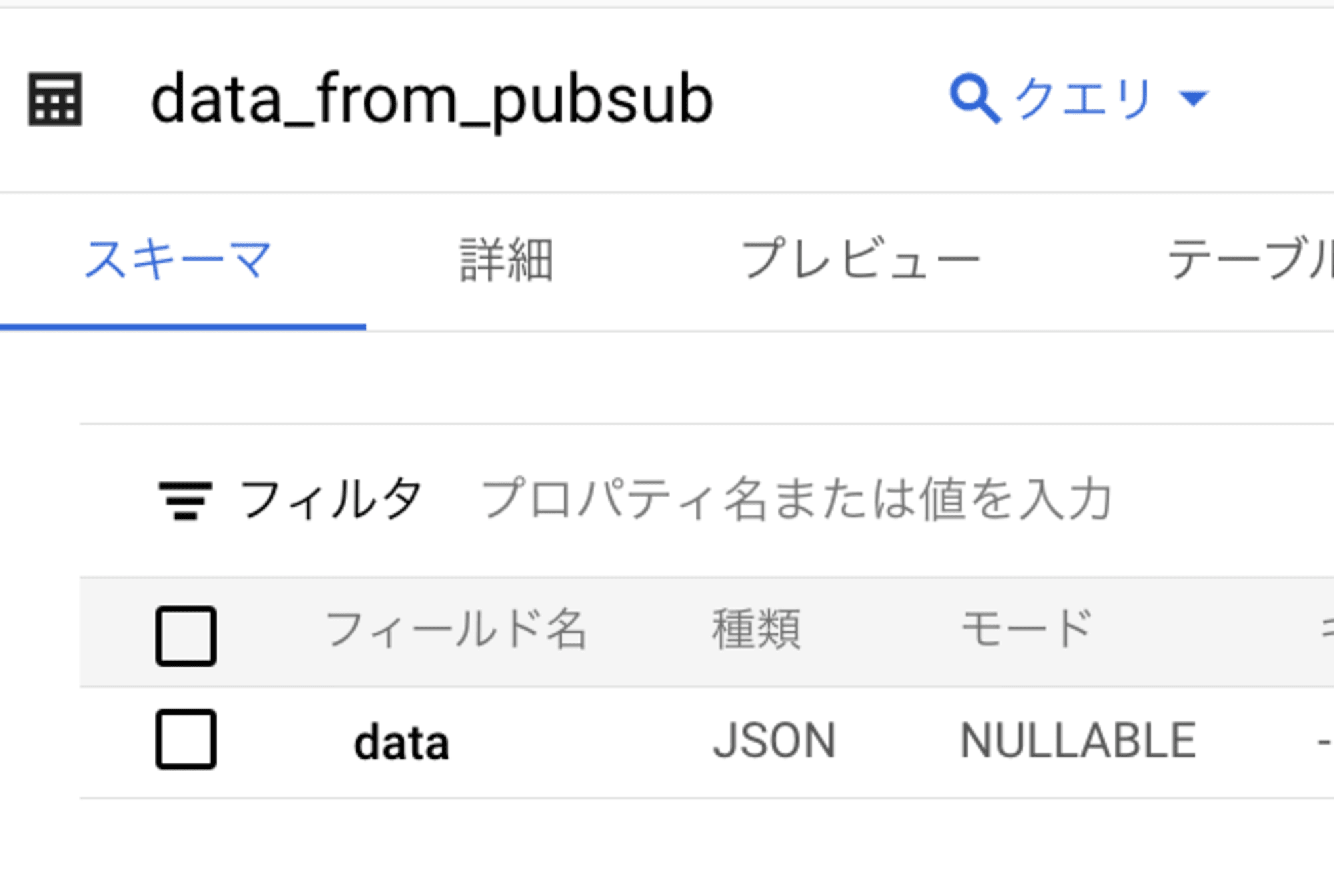
Pub/Sub からの JSON メッセーをそのまま JSON データ型の1カラムに格納します。
データを実際に利用する時に JSON 型のままだと扱いにくいことも多いと思うので、データ格納後に SQL を実行して、key 項目をカラムとする別テーブルを作成する予定です。
Pub/Sub トピックとサブスクリプションを作成
まずは、Pub/Sub から直接 BigQuery にデータを書き込むために、以下のコマンドで Pub/Sub サービスエージェントに BigQuery 編集者ロールを付与しました。
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member serviceAccount:service-[PROJECT_NO]@gcp-sa-pubsub.iam.gserviceaccount.com \
--role roles/bigquery.dataEditor
以下のコマンドで Pub/Sub トピックを作成しました。
gcloud pubsub topics create tp-pubsub2bq
続いて、以下のコマンドを実行して、BigQuery サブスクリプションを作成しました。
gcloud pubsub subscriptions create sub-pubsub2bq \
--topic tp-pubsub2bq \
--bigquery-table [PROJECT_ID]:ds_pubsub2bq.data_from_pubsub
これで準備完了です。
動作確認
準備しておいた、動作確認用の Pub/Sub メッセージ送信スクリプトを実行しました。
$ python publish.py
publish message: 1
publish message: 2
(省略)
publish message: 10
無事メッセージ送信が完了したようなので、BigQuery に格納されたか確認してみます。
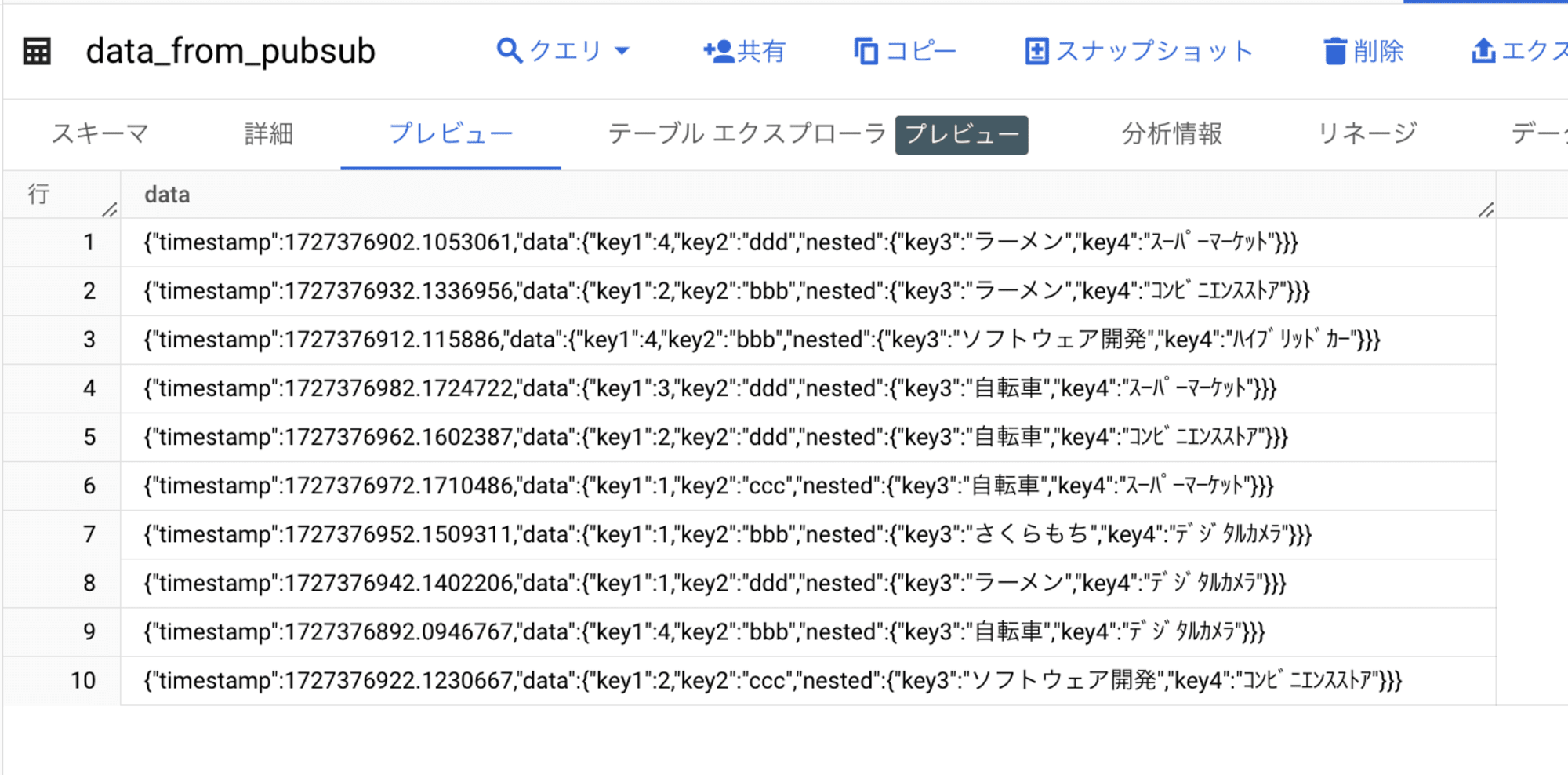
Pub/Sub の JSON メッセージがそのまま BigQuery に取り込まれました。
続いて以下の SQL を実行して、取り込んだ Pub/Sub メッセージの key 項目である timestamp, key1, key2, key3, key4 をカラムとして持つ、data_src テーブルを作成しました。
CREATE OR REPLACE TABLE ds_pubsub2bq.data_src AS
SELECT
DATETIME(TIMESTAMP_SECONDS(CAST(FLOOR(CAST(JSON_EXTRACT_SCALAR(t.data.timestamp, '$') AS FLOAT64)) AS INT64)), 'Asia/Tokyo') AS timestamp,
CAST(JSON_EXTRACT_SCALAR(t.data.data, '$.key1') AS INT64) AS key1,
CAST(JSON_EXTRACT_SCALAR(t.data.data, '$.key2') AS STRING) AS key2,
CAST(JSON_EXTRACT_SCALAR(t.data.data.nested, '$.key3') AS STRING) AS key3,
CAST(JSON_EXTRACT_SCALAR(t.data.data.nested, '$.key4') AS STRING) AS key4
FROM
ds_pubsub2bq.data_from_pubsub AS t
結果を確認してみます。
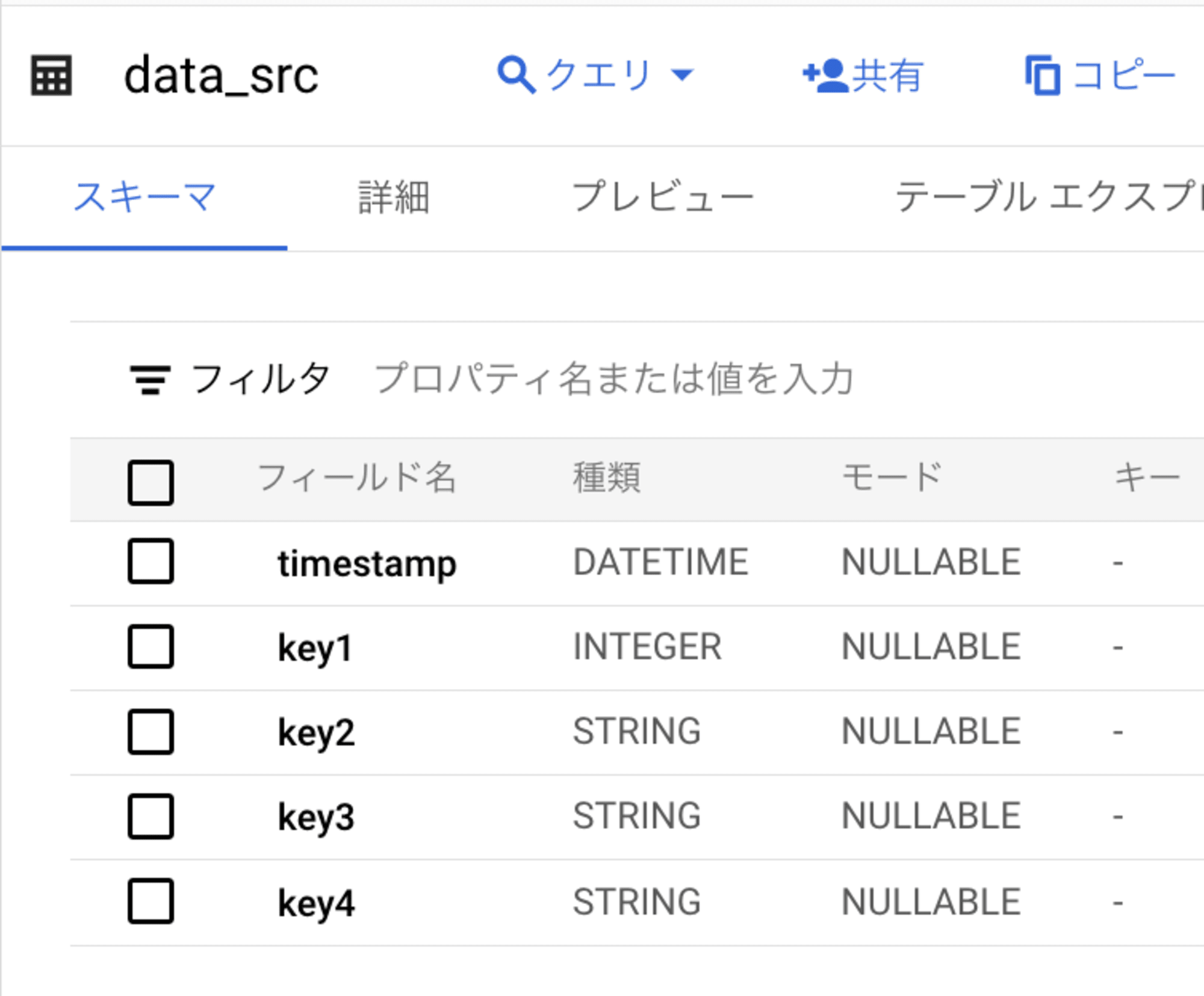

Pub/Sub メッセージを直接 BigQuery に取り込んで活用できることが確認できました。
まとめ(所感)
意外と簡単に、Pub/Sub から直接 BigQuery にデータを取り込めることが確認できました。
取り込む前にデータの加工が必要な場合や、取り込みデータの重複を許容できない場合などには、やはり Dataflow や他のバッチ処理を使う必要があると思いますが、生データを一度 BigQuery に取り込んだ後で、活用に適したデータに加工する方法も検討の余地があるのではないかと思います。
ハイパフォーマンスでスケーラビリティに優れた BigQuery は、取り込む前にデータ変換を行う ETL 処理よりも、取り込んだ後に加工する ELT 処理に適した DWH です。
PL/SQL のような手続き型言語も利用可能なので、データ取り込み後の加工処理にも柔軟に対応することができます。
また、取り込んだ生データを参照するビューを作成しておけば、活用に適した形式でデータをすぐに参照することも可能です。
行指向の RDB と違って、列指向 の DWH はリアルタイム処理は苦手なイメージがありますが、BigQuery にはリアルタイムでデータを取り込める BigQuery Write API があります。
今回検証した BigQuery サブスクリプションは、その BigQuery Write API を使用しています。BigQuery サブスクリプションを作成しておけば、コード実装の工数をかけずに BigQueryにニアリアルタイムでデータが取り込まれるので、とても便利で運用しやすいのではないかと思いました!









